CrunchDAO quant finance competitions
Creating prediction engines for a long-short hedge fund
After competing in WorldQuant International Quant Championship, I got a LinkedIn message from Jean Herelle at CrunchDAO. He asked me if I had heard about CrunchDAO’s 📈 ADIALab Market Prediction Competition, a quant finance tournament in which participants predict stock price movements using hundreds of variables over time.
Eager to learn more about time series modeling and modern quant finance techniques, I gladly signed up and dug into the data. I developed a model after a few weeks and submitted my code just before the deadline.
I’m happy to share that so far I placed 32/4407 (top 0.8%) in the world! This rank will update week-to-week as new market data is processed until the competition’s end in November. I’m excited to see where I finally place! 🥳
I had so much fun competing that I signed up for CrunchDAO’s other quant competition, the weekly DataCrunch tournament. DataCrunch is a rolling tournament in which participants model new market data as it comes in week-to-week. This gave me an opportunity to refine my modeling and development pipeline, specifically using more rigorous time series cross validation methods.
How CrunchDAO works
CrunchDAO is a decentralized autonomous organization that crowdsources data science tasks across its members. The DAO primarily works alongside financial institutions to provide signals for automated trading. The basic pipeline is shown below:
Researchers provide models ➡️ CrunchDAO aggregates into a trading signal ➡️
financial institutions execute transactions
Financial institutions profit ➡️ CrunchDAO distributes earnings ➡️ researchers
get rewarded
You can watch a nice explanation 🎥 here
Financial institutions use these predictions to rank stocks in a basket. They buy top-ranked stocks and short-sell bottom-ranked stocks, creating a net neutral portfolio. This is called a “long-short” strategy.
CrunchDAO is the best quant competition I’ve found so far. The opportunity to work with real financial data, develop machine learning models, interact with professional quants, and compete with thousands of like-minded people is amazing! The CrunchDAO crew has been super welcoming and helpful to new members like myself, and they’re constantly improving the platform. I highly recommend CrunchDAO if you’re interested in quant finance or machine learning! 🤗
The data
CrunchDAO preprocesses and anonymizes its data to encourage participants to use purely statistical models without reference to economic principles. The data has the following format, with thousands of rows of data:
| time | feature 1 | feature 2 | ... | feature 600 | returns |
|------|-----------|-----------|-----|-------------|---------|
| 1 | 0.2 | 1.1 | ... | -0.5 | 2.2 |
| 1 | -1.3 | 0.1 | ... | 0.3 | -1.1 |
| 2 | 0.9 | -0.9 | ... | 1.2 | 0.3 |
Researchers analyze the provided data to create statistical models predicting returns. Models are evaluated by the Spearman rank correlation between their return prediction and the actual returns observed in the market. This rewards models that accurately predict which stocks will be at the top and bottom of the basket in a given time period.
My models
ADIALab competition
I started my journey by working through the 📔 Jupyter notebooks provided by the CrunchDAO crew. I also connected with staff and other participants on the CrunchDAO Discord channel and read up on modern time series regression and statistical learning techniques.
My data exploration and model development for the ADIALab competition is detailed in this 📔 Jupyter notebook. In short, I created a simple linear regression model that provides moderate but stable accuracy over time. The model uses 🕸️ elastic net regularization to prevent overfitting the model to noise. Basic cross validation on a holdout dataset found optimal hyperparameters, and simple trial-and-error with the retraining rate indicated I should retrain the model every 4 time periods as new data comes in.
DataCrunch tournament
After squeezing in my final submission for the ADIALab tournament just before the deadline, I turned my attention to the DataCrunch tournament. I implemented a more robust cross validation technique for the elastic net and explored a wider range of hyperparameter values. This 📔 Jupyter notebook shows the code and data analysis for my DataCrunch models.
I implemented a conservative and an aggressive cross validation method to find optimal hyperparameters – see Section 1 in the notebook for details. In the end, I used aggressive method in order to leverage time series autocorrelation between the end of the training data and beginning of the test data.
The graph below shows an example of tuning both the lookback training period and elastic net L1 ratio to maximize Spearman correlation in the aggressive CV method. The graph shows fairly smooth behavior, indicating our CV method performs stably. The optimal hyperparameters found with the simple grid search are clear winners compared to the rest.

Performance
My elastic net model’s performance in the ADIALab competition is shown below. The red data indicates my performance on the training dataset, and the blue data indicates my performance on the test data. Luckily, my elastic net model generalizes well to new data and has generated fantastic performance recently!
Each week until mid-November will bring new market data, so I won’t know my final ranking until then. For now, I’m ranked 32/4407! 🎉
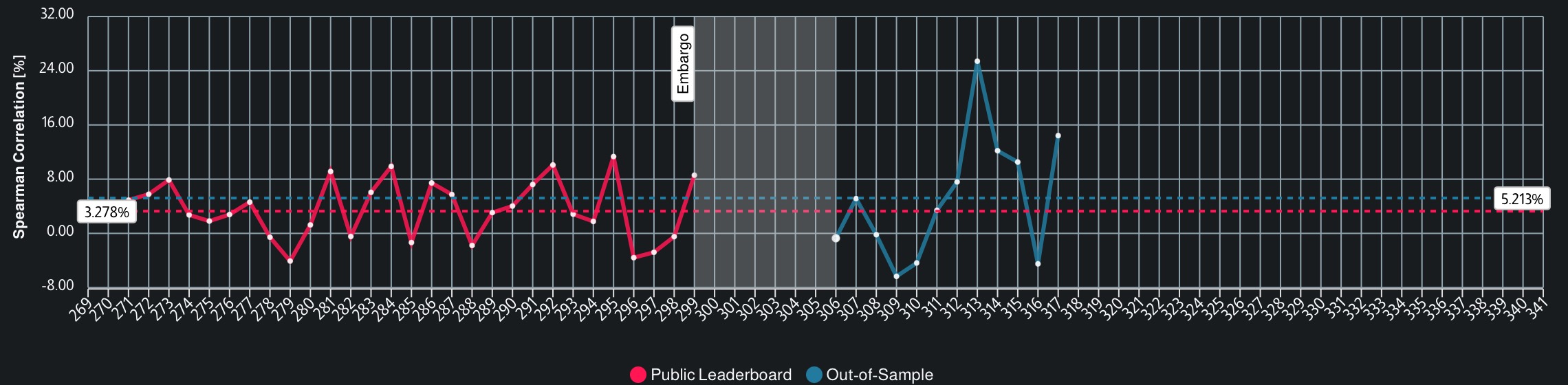
The performance in the DataCrunch competition is ongoing and follows a more complicated evaluation methodology. Right now I am ranked 125/4407, but that will increase as my model is evaluated on new data. 🚀
Conclusion
The past few months have been a blast as I’ve learned about quant finance prediction models, time series regression, cross validation strategies, and elastic net regularization. I’m so glad Jean reached out to let me know about CrunchDAO! 🙏 I highly recommend checking out their competition if you’re interested in quant finance or machine learning in general.
These competitions taught me a very important lesson in data science: simplicity and robustness are paramount! I was quite surprised to see my elastic net linear regression models rise from the top 150 of the training leaderboard to the top 40 of the test leaderboard 📈. Early in the competition, I read reports from competitors who used neural networks, decision trees, and complex ensembling techniques for their models. It was unfortunate to see some of these folks fall from the top 50 to the top 500 as new data arrived 📉. I can only imagine how much time they dedicated to training these models. In the end, they overfit the training data – a classic mistake that’s hard to avoid! This taught me to stick with simple models with few hyperparamaters, focusing on robust cross validation to ensure good generalization.
Quant funds need much more than just a prediction engine. They also need a risk management system, a trading execution algorithm, a market impact model, and more. I look forward to learning more about these topics next! Reach out via LinkedIn or email if you know of any competitions that test these skills.